
Truly effective IT Service Management needs to cover the needs of external customers, the requests of internal users, and everything else in between. One of the most critical areas IT support teams deal with, in particular, is Incident management.
Improving responses to incident management should be a goal of any IT support team – it’s key to providing top-level service. In this blog, we’ll be focusing on the mean time to resolution (MTTR) as a measurement of effectiveness and efficiency, and looking at the steps your IT teams can take to improve it.

Establish team priorities
When a major incident occurs, external customers, internal users, and even key stakeholders may well be panicking when it happens. That’s why members of the IT team are advised to keep a cool head amid the chaos. One way to do this is to know exactly what approach the team needs to take when incidents occur.
Respond
Your response doesn’t just involve investigating and identifying the cause of the incident, but also defining accountability. Not to place blame on anything, but to make it possible to learn from it later. It’s all about finding the right person/resolver group to fix the problem - or provide a suitable workaround.
Communicate
Major incidents can be damaging to the reputation of your organisation, even before you factor in the cost of an outage. Nailing your communication plan means your customers and stakeholders are clear on how you’re responding and your progress, and you can set expectations early.
That’s why it’s essential to get a well-balanced communication out to the business community; giving too much information can sometimes be just as bad as, if not worse, than providing little or poor communication.
Collaborate
Working as a team is essential to solving issues faster and streamlining your processes. Removing barriers to collaboration and information sharing means you’ll resolve faster.
Improve
The bigger the incident, the bigger (and often more negative) the impact. On the other hand, you can ultimately learn from it, meaning you’ll be able to do much more in the future to prevent problems from escalating into full-blown incidents and outages. This stage can be forgotten in the rush of resolving an incident, but it will lead to fewer incidents in the future - giving you opportunities to refine your incident management processes.
When the IT support team reacts to incidents and communicates with others calmly, it’s a win for everyone.
Define paths and processes
To improve your mean time to resolution, you need an effective and standardised way to measure it. To do that, you’ll need standard processes and paths of communication in place that grant your teams the flexibility to adapt, depending on the nature of the incident.
That’s why knowing what each step of the process looks like, and who’s responsible for communicating updates to stakeholders is key. If possible, set out guidelines in advance for your messaging, so there aren’t any delays in communication - allowing you to resolve the incident faster.
A good practice for this is to break it down into 5 distinct stages:
- Identify and communicate
- Investigate and diagnose
- Provide a workaround where needed
- Resolve and recover
- Closure
![]()
Incident swarming with ChatOps
According to a past Forrester study, 70% of the time working on incident management is spent during the investigation and diagnosis stages. With more time being spent on these stages than any other, this is the area you should focus on when it comes to reducing the time spent from identifying a problem to being able to close it.
A great way to make improvements here is to incorporate ChatOps into your workflows. There are several ways you could do this. In this example, we’ll examine how integrating Atlassian’s Jira Service Management with Slack helps IT support teams to collaborate in real-time.
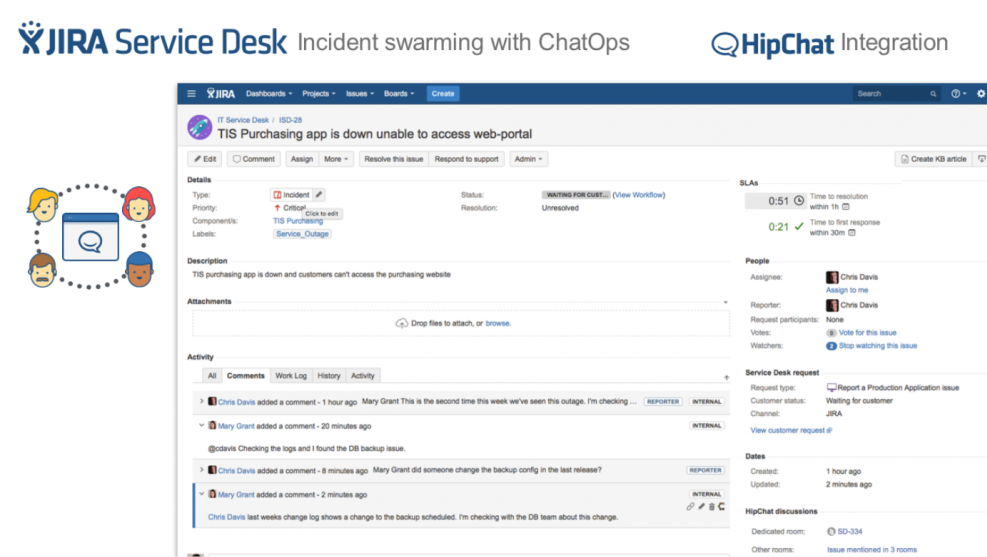
Slack offers several integrations, including integration with monitoring tools and, of course, Jira Service Management. By bringing chat into your service desk solution, your teams can discover issues, discuss them, triage them, and ultimately resolve them all in one place, with full visibility and no need for clunky email chains.
You can even turn tickets for major incidents into dedicated Slack rooms. Invite the right people so your teams can swarm on incidents more quickly. Everyone will know the progress, as Jira Service Management updates will be communicated automatically to the room. This centralisation of information and communication will save support teams significant time.
Let the experts help
With most IT organisations today supporting self-service within ITSM, the importance of having a comprehensive knowledge base cannot be overlooked. The more articles available to your users, the more answers they’ll be able to find themselves. Not only that, but they’ll be logging fewer tickets, meaning IT support teams can dedicate more of their time to resolving major incidents faster.
Self-service is becoming increasingly popular, with an impressive 90% of users preferring it over traditional options. This choice has the added benefit of reducing costs and delivering a notably higher satisfaction rate!
Having a knowledge base that integrates closely with your service desk will allow you to take this even further. But let’s return to our earlier example of Jira Service Management momentarily. When IT teams use Confluence alongside Jira Service Management to collaboratively build a knowledge base (and integrate the two tools together), they can start automating the self-service side of the service desk.
When a user creates a ticket, Jira Service Management will suggest articles based on what they’re typing on that ticket – and the system will learn which ones work for the future.
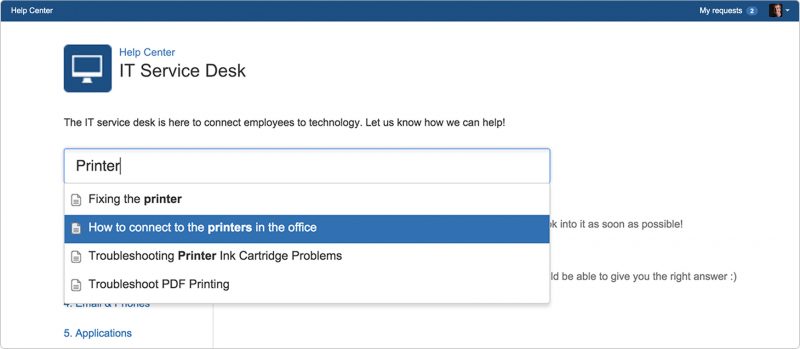
Bringing a level of automation to self-service in this way will not only keep your users happy with quick, smart self-service, but also promote knowledge sharing - making it easier than ever for teams to collaborate and work smarter and faster.
Published: Apr 11, 2018
Updated: Mar 25, 2024
